Proving the ROI of Agentic AI in Financial Services

Every CIO and Head of Transformation in financial services is facing the same question from their board: "We're spending millions on AI - what are we getting back?"
It's a fair question. And right now, most teams can't answer it with numbers.
The problem isn't that agentic AI doesn't work. Multi-agent systems are already processing RFPs, monitoring compliance, and automating document workflows across the industry. The problem is that the economics of these systems are fundamentally different from anything enterprises have managed before. When an agent autonomously decides to query a database, call an external API, loop back to refine its reasoning, and then hand off to a second agent, the cost is not a simple line item. It's a dynamic, multi-variable equation that traditional FinOps tools were never built to handle.
This post walks through how to solve that problem. We'll show two real financial services use cases - RFP processing and Anti-Money Laundering (AML) compliance monitoring, and break down the business KPIs that matter, how to track them, and how to build the observability and governance infrastructure to prove ROI to your leadership team.
We're writing this jointly because solving this requires two things working together: an engineering platform to build, debug, and optimize agents (LangChain, LangSmith, and LangGraph), and an economic intelligence platform to measure their business value and govern their costs (Pay-i).
The real cost challenge: why traditional monitoring falls short
If you've built a multi-agent system, you already know the cost structure looks nothing like a traditional SaaS application. A single agent invocation might involve multiple LLM calls across different providers, tool calls to internal and external APIs, retries and reasoning loops, and orchestration overhead — all of which vary per execution.
LangSmith gives engineering teams full visibility into this complexity. Every agent execution is captured as a trace - a complete record of every LLM call, tool invocation, and intermediate step. LangSmith's cost tracking automatically computes token usage and spend per trace, broken down by model and provider. Its prebuilt dashboards surface aggregate cost, latency, error rates, and token usage trends over time. And its custom dashboards let you slice that data by any dimension that matters to your team: such as by model or user segment.
But here's what engineering-level observability alone can't tell you: is this agent actually delivering business value? That's where Pay-i comes in. Pay-i looks across multiple agents to connect the cost of every GenAI use case to measurable business outcomes. It researches and identifies what constitutes “success” for a given workflow. It then defines business KPIs with industry-appropriate goals, and tracks how your use case is scoring on those KPIs in real time. It quantifies the impact to your business either in time saved or value generated using real world business metrics, and gives you immediate suggestions on how to improve your ROI.
Together, these platforms close the loop between "what is this agent doing?" and "what is this agent worth?"
Use case 1: RFP processing automation
The business problem
Financial services institutions field a constant stream of RFPs from corporate and institutional clients. Each one arrives as a package of PDFs, Word documents, and annexes, and requires responses that are precisely structured, fully cited, and reviewed by SMEs across Compliance, Risk, InfoSec, Legal, and Product.
Today, this process is almost entirely manual. A proposal team reads through the RFP, maps requirements to internal capabilities, drafts responses, chases down SMEs for review, and assembles the final submission. A single complex RFP can consume hundreds of hours across multiple departments. Multiply that by the volume most institutions handle, and you're looking at one of the largest hidden labor costs in the organization.
An agentic system built with LangChain and LangGraph can automate the heavy lifting: ingesting the RFP package, extracting requirements, mapping them to approved internal content, generating a structured response draft with citations to source documents, and flagging gaps for human review. The human SMEs still own the final sign-off — but instead of starting from scratch, they're reviewing and refining a draft that's already 65% ready to submit.
The KPIs that matter

Pay-i will monitor the execution of the agents in the RFP use case and will dynamically determine applicable KPIs and industry benchmarked goals, backed by annotated research. You can also specify your own KPIs, some of which Pay-i can automatically score, and others which can collect data from your existing systems. Some example KPIs for an RFP use case might include:
Requirements extraction accuracy (Type: Percentage, Goal: 95%). The percentage of key requirements — scope, service levels, pricing format, security clauses, regulatory provisions that the agent correctly identifies and extracts from the incoming RFP package. Modern document AI benchmarks consistently show 90–99% accuracy for structured extraction. For financial services RFPs, 95% is the threshold where the agent saves time rather than creating rework.
Response draft approved without major revisions (Type: Boolean, Goal: 65%). Whether the AI-generated draft passes SME review without requiring substantial rework. Industry data on leading AI RFP tools shows that 60–66% of AI-generated answers require no edits when reviewed by proposal managers. For financial services, where compliance precision is critical, 65% represents a meaningful productivity gain while maintaining appropriate human oversight.
SME reviewer satisfaction (Type: Likert5, Goal: 4.0/5.0). A Likert-scale rating from the Compliance, Risk, InfoSec, Legal, and Product reviewers on overall quality, citation accuracy, and usefulness of the draft for their workflow. If SMEs don't trust the output, they'll redo the work from scratch and the agent delivers no value regardless of its technical accuracy.
Source citation completeness (Type: Percentage, Goal: 95%). Whether every substantive claim in the response includes a traceable citation to a specific internal source document. This is a credibility and audit requirement. In financial services RFPs, unsupported claims about security controls or regulatory compliance can create legal liability.
Why these KPIs matter to the CIO
These aren't engineering metrics; they're business metrics. Requirements extraction accuracy, response draft approval rates, and source citation completeness directly correlate to labor savings and win rates. Every draft that passes without major revision may represent dozens of SME-hours recovered. And the fabricated content and citation KPIs are risk metrics that translate directly to compliance exposure in dollars.
Pay-i tracks all of these KPIs against the cost of the entire use case, across all involved agents and related resources. It monitors the versions of your agents so the transformation team can see exactly how a model swap or prompt change affected both cost and business performance. Pay-i then researches your business segment to define a “Value Policy”, which translates KPI data and metrics about the use case into quantified business value and time savings.
When the CIO asks "what are we getting back?", the answer is a dashboard showing cost per RFP processed, KPI performance trends, and calculated ROI.
Use case 2: AML compliance monitoring
The business problem
Anti-money laundering compliance is one of financial services' most operationally expensive regulatory obligations. Transaction monitoring systems generate thousands of alerts daily, but the vast majority (often 95% or more) are false positives. Each alert still requires investigation: an analyst must review transaction patterns, check customer profiles, pull contextual data from multiple systems, and document findings.
The result is a compliance function that consumes enormous resources while still struggling to catch genuinely suspicious activity. Sophisticated laundering schemes adapt faster than rule-based detection systems can evolve. Regulators are increasing scrutiny, with fines for inadequate AML programs running into the billions.
A multi-agent system can transform this workflow. One agent triages incoming alerts, pulling contextual data and scoring risk. A second performs deeper investigation on escalated cases, synthesizing data from internal systems and external databases. A third generates Suspicious Activity Report (SAR) drafts when warranted. Human analysts retain decision authority on escalations and SAR filings, but the agents dramatically reduce the manual burden on low-risk alerts and accelerate investigation on genuine threats.
The KPIs that matter

Though Pay-i will tailor its suggested KPIs to your business and needs, these are some example KPIs that might be applicable for AML Compliance Monitoring:
False positive reduction rate (Type: Percentage, Goal: 60% reduction). The percentage decrease in alerts requiring full manual investigation after agent triage. A 60% reduction may represent hundreds of analyst-hours recovered per month. This is the primary cost justification for the system.
Average investigation time (Type: Number (minutes), Goal: 50% reduction). The time from alert generation to completed investigation for cases that still require analyst review. The agent accelerates this by pre-gathering contextual data, summarizing transaction patterns, and highlighting relevant risk factors, which allows the analyst to start with a briefing rather than a blank screen.
SAR draft quality score (Type: Likert5, Goal: 4.0/5.0). A reviewer rating on the completeness, accuracy, and regulatory compliance of agent-generated SAR drafts. A well-drafted SAR may save the compliance team hours of documentation work per filing while ensuring the institution meets its regulatory obligations.
Regulatory audit readiness (Type: Boolean, Goal: 95%). Whether the agent's investigation documentation (reasoning trail, data sources accessed, and conclusions reached) meets the standard required for regulatory examination. Regulators don't just want the right outcome. They want a documented, defensible process.
Why these KPIs matter to the CIO
AML compliance is both a cost center and a risk function. The CIO and Head of Transformation need to demonstrate that agentic automation reduces operational cost without increasing regulatory exposure. At the same time, this process is unlikely to be fully automated; it will require continued human oversight. Therefore, the ‘value’ for this use case is really in how much time it saves the human handlers, who are now reviewing the work of the agents and making small tweaks instead of writing everything themselves from scratch. Pay-i can quantify this time savings, taking into account how long employees at your company would typically take to perform each task compared to the time it takes for all of the agents to execute across the entire use case followed by human review and correction.
Under the hood: multi-agent architecture
Both use cases are implemented as multi-agent systems; they consist of coordinated teams of specialized agents that reason, hand off, and collaborate, rather than relying on monolithic LLM calls.
Built with LangChain, LangGraph, and LangSmith
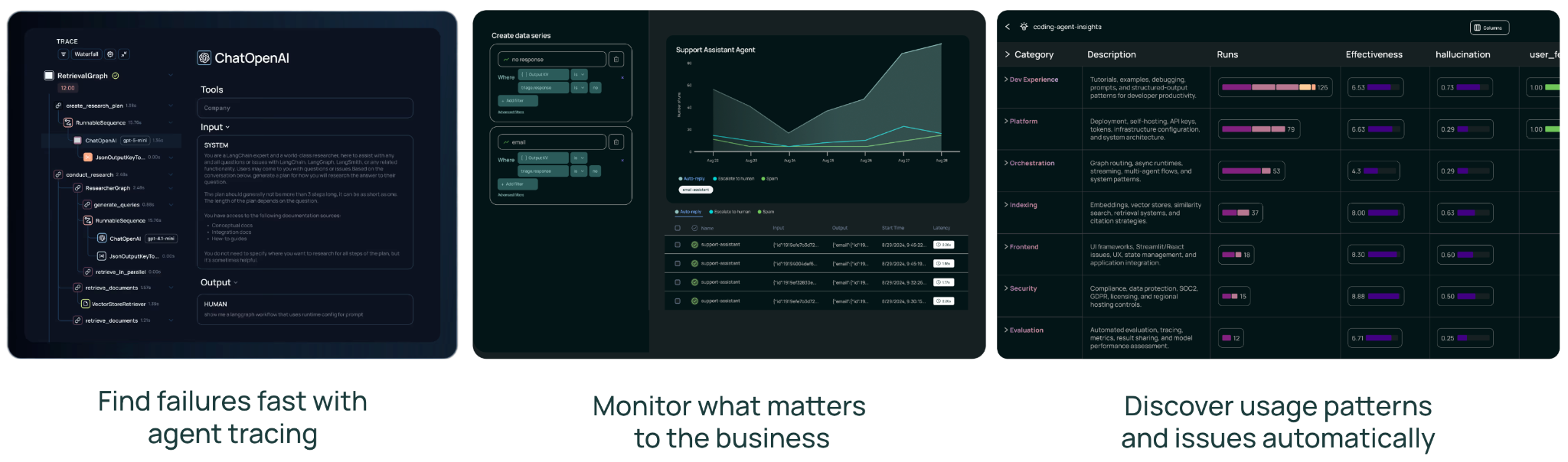
LangGraph orchestrates agent workflows as stateful graphs: each node represents a specialized agent or tool call, with conditional edges that route based on the agent's reasoning. For the RFP use case, this means a requirements extraction agent, a content mapping agent, a draft generation agent, and a gap detection agent, each with its own tools and prompts, coordinated through a shared state.
LangSmith provides the observability layer that makes these complex workflows debuggable and optimizable:
Tracing. Every agent execution produces a full trace, a hierarchical view of every LLM call, tool invocation, and intermediate step. When a reviewer flags a bad citation in an RFP draft, an engineer can pull up the trace, see exactly which agent produced that citation, what context it had, and where the reasoning went wrong. Without this, debugging a multi-agent system is guesswork.
Cost tracking. LangSmith automatically computes token usage and cost for every trace, broken down by model and provider. This is critical for multi-agent systems that mix models (a cheaper model for routine extraction, a more capable model for nuanced compliance language). Teams can see exactly where spend is going and make informed routing decisions.
Dashboards and monitoring. Prebuilt dashboards track trace volume, latency (P50 and P99), error rates, token usage, and cost trends over time. Custom dashboards let teams build views tailored to their use case, for example, a dashboard showing cost per RFP processed alongside first-pass approval rates, or AML alert triage latency broken down by risk tier.
Insights Agent. LangSmith's Insights Agent automatically analyzes traces to surface usage patterns and failure modes. Instead of manually reviewing thousands of traces, teams get an executive summary of the most common behaviors, categorized hierarchically, with drill-down to individual traces. For an AML system processing thousands of alerts daily, this is the difference between knowing there's a problem and knowing what the problem is.
Filtering and automation. Advanced trace filtering lets teams isolate specific failure patterns, for example, all traces where the RFP agent substituted generic terminology instead of mirroring the client's language. Automation rules can trigger alerts or webhooks when specific conditions are met, enabling proactive monitoring rather than reactive debugging.
These systems also call non-LangChain components where needed: internal document management systems, compliance databases, external data providers, and legacy APIs. LangSmith traces these external calls as tool invocations within the same trace, maintaining end-to-end visibility even when the agent's execution spans multiple systems.
Measured and governed with Pay-i
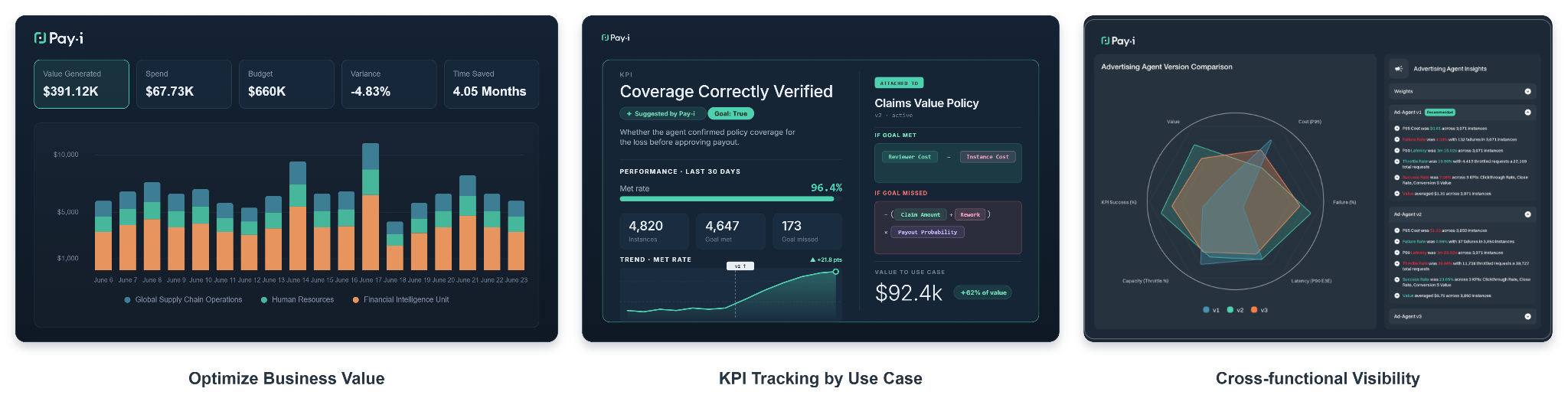
Pay-i layers on top of this architecture as the economic intelligence and governance platform:
KPI tracking by use case. Pay-i suggests and lets teams define custom KPIs for each use case. For many KPIs it can assess agent performance itself and provide scores, or it can connect to your existing systems to provide scores for custom KPIs. Scores are correlated with use case versions, so the team can see exactly how a prompt change or model swap affected business performance.
Value policies and ROI measurement. Pay-i computes both "value generated" (in dollars) and "time saved" (in hours) by combining KPI data with metrics and cost data with business logic specific to your institution. The result is a concrete ROI number: "This agent saved $X and Y hours this quarter, at a cost of $Z." This directly informs organizations on which initiatives will be effective to scale and which ones to cut.
Real-time cost governance. Pay-i enforces budget limits per use case. If a single agent execution enters a runaway loop and threatens to exceed a cost threshold, Pay-i interdicts the call in real time. This is the safety net that lets the CIO scale agentic systems without fear of cost blow-ups.
Margin and revenue control. Pay-i tracks the full unit economics for all agent activities, independent of provider, framework, or model, and shows you the percentile breakdown of typical and outlier interactions. This helps organizations that charge for their AI solutions know exactly how to price and their expected margins.
Cross-functional visibility. Engineers see API-level cost breakdowns and latency. Product owners see KPI trends and use case performance. Finance sees forecasts, actuals, and variance reporting. The CIO sees executive dashboards with ROI by business unit. Everyone works from the same data, aligned to the same outcomes.
Getting started
If you are running or planning agentic AI in financial services, the playbook is straightforward:
- Build your agents with LangChain and LangGraph. Use LangGraph's stateful orchestration to coordinate multi-agent workflows. Integrate with your internal systems using LangChain's tool-use framework.
- Instrument from day one with LangSmith. Don't wait until production to add observability. Trace every execution in development and staging. Use cost tracking and dashboards to establish baselines before you scale.
- Drive prioritization and scale with Pay-i. Pay-i works with your business stakeholders to identify the metrics that matter from the get go, and then ensures that each new version of your use case or agent gets you closer to your business goals.
- Optimize using both platforms together. Use LangSmith's traces and Insights Agent to find your performance hotspots. Use Pay-i's KPI and value correlation to identify where optimization efforts will have the highest business impact and which version performs best before you scale.
- Govern and prove. Set budget controls in Pay-i to de-risk production scale-up. Use Pay-i's executive dashboards to report ROI in the language your board understands: dollars saved, hours recovered, risk reduced.
The financial services institutions that will lead in agentic AI aren't the ones building the most sophisticated agents. They are the ones that can prove their agents deliver measurable business value and scale with confidence, supported by the observability and governance infrastructure that backs it up.